

Dans cet article, nous allons voir comment choisir la fonction de perte lors de l’entraînement d’un réseau de neurones.
De nombreuses fonction deperte existent en Machine Learning et il est important de bien les choisir.
Cette fonction est principalement utilisée dans les Réseaux de Neurones.
Donc quand tu entends fonction de perte, tu dois comprendre Deep Learning.
C’est une des composantes essentielles qui te permet d’entraîner ton modèle.
Mais avant toute chose, à quoi ça sert une fonction de perte ?
La fonction de perte permet de calculer l’erreur entre les prédictions de ton modèle et les valeurs réelles.
Plus la perte baisse, plus le modèle est performant !
Pendant l’entraînement, cela permet au modèle de savoir s’il avance dans la bonne direction ou non.
L’objectif étant que perte soit le plus proche possible de zéro.
Cependant, il y a plusieurs manière de calculer l’erreur entre les prédictions et les valeurs réelles.
Cela va dépendre essentiellement de la tâche que tu dois résoudre (mais pas que).
Je te propose tout d’abord de plonger dans un court rappel sur les classes et les labels qui vont nous permettre de comprendre comment choisir la fonction de perte.
Classe vs label
Souvent confondu, la classe et le label sont deux concepts important du Machine Learning.
Le label est la donnée à prédire dans un dataset.
La classe représente un des choix possible lors de la prédiction.
Par exemple, si tu dois prédire l’espèce d’un animal (chien ou chat) alors :
- l’espèce est le label
- chien et chat sont les deux classes
Si tu es débutant en Deep Learning, tu rencontreras le plus souvent des problèmes à un label et deux classes.
C’est la classification binaire.
Ensuite, plus tu prendra de l’expérience, plus tu rencontreras des problèmes à classification multi-classes.
Selon le type de problème auquel tu feras face, tu devras choisir la bonne fonction de perte !
Si tu veux en savoir plus sur les différences entre classe et label, je t’invite à lire notre article approfondit sur le sujet !
Maintenant, passons à comment choisir la fonction de perte ☄️
Classification Binaire – Comment Choisir la Fonction de Perte
La Classification Binaire est le fait de classifier des données dans un label contenant seulement deux classes.
Dans ce cas, le modèle va prédire la probabilité d’appartenir à chacune des classes.
Pour ce type de tâches, ta dernière couche doit posséder une fonction d’activation sigmoïde (voir notre article sur les fonctions d’activation).
Binary Cross Entropy
La fonction de perte Cross Entropy est sûrement celle dont tu auras le plus besoin.
Elle est utilisée en classification Binaire ET en classification multi-classes !
La Binary Cross Entropy est un cas spécifique de la Cross Entropy.
Elle conçu pour être utilisée uniquement sur les tâches de classification binaire.
Ici tes deux classes doivent être représentées par des 0 et des 1.
Pour l’utiliser avec Keras :
model.compile(loss='binary_crossentropy', optimizer=...)Avec TensorFlow :
loss = tf.keras.losses.BinaryCrossentropy()
loss(y_true, y_pred)et avec PyTorch :
loss = nn.BCELoss()
loss(y_pred, y_true)Et pour les mathématiciens, voilà la formule de la Cross Entropy :
def binary_cross_entropy_loss(y_pred, y_true):
return -np.sum(y_true * np.log(y_pred))Reprenons notre exemple : tu as le label espèce et les deux classes chat et chien.
Chaque image est représentée ainsi : [1, 0] pour les chats et [0, 1] pour les chiens.
Si une de tes images représente un chien et que ton modèle prédit que c’est un chien avec 0.85% de confiance, le calcul de la perte est le suivant :
Binary Cross Entropy = -(0 x log(0.15) + 1 x log(0.85))
= 0.07
Hinge Loss
La Hinge Loss, peu connue, est une bonne alternative à la Binary Cross Entropy.
Mais comment choisir entre les deux fonctions ?
Avec la Hinge Loss, tes deux classes doivent être représentées par des -1 et des 1.
La Hinge Loss est un bon choix lorsque les données sont complexes (non linéairement séparable) et que le nombre d’exemples négatifs est beaucoup plus important que le nombre d’exemples positifs.
Elle est notamment utilisée dans les Supports Vector Machine (SVM).
La Binary Cross entropy au contraire, est un bon choix lorsque l’on travaille avec des réseaux de neurones et que l’objectif est de prédire des probabilités.
Attention, si tu utilise la Hinge Loss ta dernière couche doit posséder une fonction d’activation tanh pour donner une valeur entre -1 et 1.
Pour utiliser la Hinge Loss avec Keras et TensorFlow :
loss = tf.keras.losses.Hinge()
loss(y_true, y_pred)Avec PyTorch :
loss = nn.HingeEmbeddingLoss()
loss(y_pred, y_true)Et voilà la formule mathématique :
def hinge_loss(y_pred, y_true):
return np.maximum(0, 1 - y_true * y_pred)On reprend notre exemple : tu as le label espèce et les deux classes chat et chien.
Chaque image est représentée ainsi : -1 pour les chats et 1 pour les chiens.
Si une de tes images représente un chien et que ton modèle prédit que c’est un chien avec 0.85% de confiance, le calcul de la perte est le suivant :
Hinge Loss = np.maximum(0, 1 - 1 * 0.85)
= np.maximum(0, 0.15)
= 0.15
Classification Multi-classes – Comment Choisir la Fonction de Perte
La Classification Multi-classes est le fait de classifier des données dans un label contenant deux classes ou plus.
Dans ce cas aussi, le modèle va prédire la probabilité d’appartenir à chacune des classes.
Cross Entropy
La Cross Entropy est une des fonctions de perte les plus populaires.
Je le répète, elle est utilisées en classification Binaire ET en classification multi-classes !
Avec cette fonction, chacune de tes classes doit être représentée par un seul chiffre : 0, 1, 2 etc.
Pour l’utiliser avec Keras :
model.compile(loss='sparse_categorical_crossentropy', optimizer=...)Avec TensorFlow :
loss = tf.keras.losses.SparseCategoricalCrossentropy()
loss(y_pred, y_true)et avec PyTorch :
loss = nn.CrossEntropyLoss()
loss(y_pred, y_true)La formule mathématique de la Cross Entropy est similaire à celle de la Binary Cross Entropy :
def cross_entropy_loss(y_pred, y_true):
return -np.sum(y_true * np.log(y_pred))Imaginons cette fois que l’on doit prédire 3 espèces : chien, chat et canard.
Pour chaque image on a : [1, 0, 0] pour les chats, [0, 1, 0] pour les chiens et [0, 0, 1] pour les canards.
Si une de tes images représente un chat et que ton modèle prédit que c’est un canard avec 0.72% de confiance, le calcul de la perte est le suivant :
Categorical Cross Entropy = -(1 x log(0.16) + 0 x log(0.12) + 0 x log(0.72))
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
= 0.79
Kullback-Leibler Divergence
La Kullback-Leibler Divergence, aussi appelé KL Divergence, est utilisée pour la classification mais aussi pour des tâches de générations.
Alors que choisir entre la KL Divergence et la Categorical Cross Entropy ?
Le choix va dépendre de toi.
En pratique, ces deux formules donne un résultat très similaire.
Je te conseille de commencer par la Categorical Cross Entropy. Puis, lors de l’optimisation de ton modèle, de tester la KL Divergence.
Pour l’utiliser avec Keras et TensorFlow :
loss = tf.keras.losses.KLDivergence
loss(y_pred, y_true)Pour l’utiliser avec PyTorch :
loss = nn.KLDivLoss()
loss(y_pred, y_true)Et finalement, voilà la formule mathématique :
def kullback_leibler_divergence(y_pred, y_true):
return y_true * np.log(y_true / y_pred)Tâches de Régression – Comment Choisir la Fonction de Perte
La Régression est le fait de prédire une valeur et non une probabilité.
Dans ce cas, il n’y a aucune classe, seulement un label.
Mean Squared Error
La Mean Squared Error (MSE), en français erreur quadratique moyenne, est une des fonctions de perte les plus utilisées dans les problèmes de régression.
Elle calcule la différence moyenne au carré entre les valeurs prédites et les valeurs réelles.
Pour l’utiliser avec Keras et TensorFlow :
loss = tf.keras.losses.MeanSquaredError()
loss(y_true, y_pred)Avec PyTorch :
loss = nn.MSELoss()
loss(y_pred, y_true)Et voilà la formule mathématique :
def mean_squared_error(y_pred, y_true):
return np.mean((y_pred - y_true) ** 2)Prenons un exemple : tu dois prédire le prix de l’action Google.
Le prix est présenté en euros.
Si vendredi dernier l’action était à 100€ et que ton modèle a prédit que l’action serait à 92€ , le calcul de la perte est le suivant :
Mean Squared Error = (100 - 92)**2
= 64
Tu peux voir que la perte est très éloignée de 0.
C’est parce que, ici, on ne calcule plus la perte sur des probabilités mais sur des valeurs réelles.
Pour évaluer la qualité de ce résultat, il est important de connaître le contexte du problème.
Par exemple, ici, le résultat du calcul de la perte est de 64.
C’est un nombre important.
On pourrait croire que le modèle est mauvais.
Mais si l’action est de 100€, et qu’il faut prédire ce prix, on peut s’attendre à ce qu’un bon modèle ait une différence un peu plus grande que 5, voire plus grande que 10.
Si la différence entre la prédiction et la valeur réelle est entre 5 et 10, la perte sera, elle, entre 25 et 100.
On comprend alors qu’une perte de 64 indique un modèle avec une bonne précision.
Pour te rendre compte de se phénomène, tu peux calculer la perte sur la prédiction d’un investissement :
- valeur réelle
= 1,2 milliard d'euros - prédiction
= 1,19 milliards d'euros
Tu verras que la valeur de la perte est énorme. Mais, en contextualisant ce résultat, on se rend compte que la prédiction est très précise.
Dans une tâche de Régression, avant d’évaluer la perte, établit le contexte du problème.
Mean Absolute Error
La deuxième fonction la plus utilisée pour les tâches de régression est la Mean Absolute Error (MAE), en français l’erreur absolue moyenne.
Elle calcule la différence absolue moyenne entre les valeurs prédites et les valeurs réelles.
Pour l’utiliser avec Keras et TensorFlow :
loss = tf.keras.losses.MeanAbsoluteError()
loss(y_true, y_pred)Avec PyTorch :
loss = nn.L1Loss()
loss(y_pred, y_true)Et voilà la formule mathématique :
def mean_absolute_error(y_pred, y_true):
return np.mean(np.abs(y_pred - y_true))Reprenons notre exemple : tu dois prédire le prix de l’action Google.
Si vendredi dernier l’action était à 100€ et que ton modèle a prédit que l’action serait à 92€ , le calcul de la perte est le suivant :
Mean Absolute Error = abs(100 - 92)
= 8
Huber Loss
La Huber Loss est une fonction moins connue et pourtant, très efficace.
Elle est particulièrement utile lorsque ton dataset contient beaucoup d’outliers (des données très éloignées de la moyenne).
Voilà comment l’utiliser avec Keras et TensorFlow :
loss = tf.keras.losses.Huber()
loss(y_true, y_pred)Avec PyTorch :
loss = nn.HuberLoss()
loss(y_pred, y_true)Et la formule mathématique (plus complexe que les précédentes) :
def huber_loss(y_true, y_pred, delta=1.0):
residual = y_true - y_pred
condition = np.abs(residual) <= delta
quadratic_loss = 0.5 * residual**2
linear_loss = delta * (np.abs(residual) - 0.5 * delta)
return np.mean(np.where(condition, quadratic_loss, linear_loss))Reprenons une fois de plus notre exemple : tu dois prédire le prix de l’action Google.
Si vendredi dernier l’action était à 100€ et que ton modèle a prédit que l’action serait à 92€ , le calcul de la perte est le suivant :
Huber Loss = 0.5 * min(abs(100 - 92), 1.0)**2 + 1.0 * ( – abs(100 - 92)min(abs(100 - 92), 1.0))
= 7.5
Résumé – Comment Choisir la Fonction de Perte
Lors de son entraînement, un réseau de neurones à pour but d’amener la perte le plus proche possible de zéro.
Il est nécessaire de savoir comment choisir la fonction de perte, sans quoi ton modèle risque de ne jamais faire ce que tu lui à demander.
Attention pour les tâche de régression la qualité du résultat de ta perte dépend de ton contexte (voir exemple du Mean Squared Error).
Ci-dessous, je mets à ta disposition mon tableau pour savoir quelle fonction de perte utiliser selon le type de problème et la fonction d’activation choisis dans la dernière couche de ton modèle.
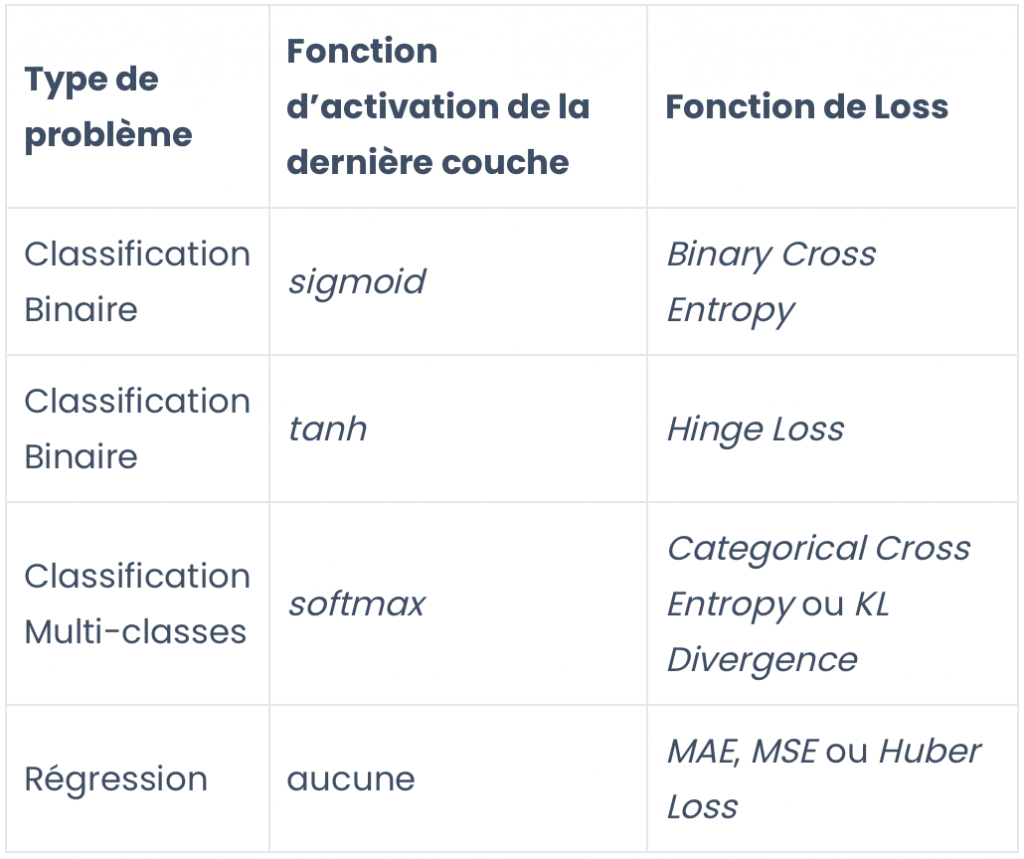
Et si ton modèle n’arrive pas à s’approcher de zéro pose toi ces trois questions :
- Quel est mon type de problème ?
- Ai-je choisis la bonne fonction de perte ?
- Si je fais de la régression, quel est le contexte de mon problème ?
La fonction de loss est un élément essentiel des réseaux de neurones – mais ce n’est pas le seul !
Si tu veux approfondir tes connaissances dans le domaine, tu peux accéder à mon Plan d’action pour Maîtriser les Réseaux de neurones.
Un programme de 7 cours gratuits que j’ai préparé pour te guider dans ton parcours pour apprendre le Deep Learning.
Si ça t’intéresse, clique ici :
sources :
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :



