

Dans cet article, je te propose de réaliser ton premier projet Data Science pour bien débuter dans ce domaine.
La Data Science est l’utilisation de techniques et d’outils modernes pour analyser et extraire des informations de données.
Dans ce projet on va utiliser les librairies Python : Pandas, Numpy & Scikit-learn.
Tu verras ici :
- Premiers pas en Data Science
- Techniques d’analyse de données
- Algorithmes de Machine Learning
C’est parti !
Charger ses données – Projet Data Science
Premier pas
Pour ce projet nous allons prendre un dataset bien connu de la Data Science : le Boston Housing Dataset. Ce dataset répertorie des données des logements de Boston.
L’objectif est d’arrivée à prédire le prix d’un logement à partir de ses informations.
On vous recommande d’utiliser un Notebook Python pour suivre ce projet. Vous pourrez ainsi copier/coller facilement les lignes de codes qui vont suivre. Chez Inside Machine Learning, on vous recommande d’utiliser Google Colab, une option simple (pas besoin d’installation) et gratuite.
La première étape est d’importer nos données dans notre environnement de code.
Pour ça on va utiliser une librairie de base : Pandas. Et télécharger notre dataset directement depuis son URL, dans notre environnement :
import pandas as pd
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)On a maintenant accès à notre Dataframe Pandas qui contient toutes nos données.
Néanmoins pour utiliser la librairie Scikit-learn, on a besoin de transformer ce Dataframe en Array Numpy. Effectivement la librairie Pandas n’est pas compatible avec Scikit-learn.
On va donc transformer ce Dataframe en Array Numpy. Et je te propose de directement créer deux Arrays :
- les X features (les informations des logement)
- la Y target (le prix à prédire)
import numpy as np
X_full = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
Y = raw_df.values[1::2, 2]Notre Dataset
Ensuite on peut afficher quelques informations sur notre dataset. Notamment la dimension de nos Arrays :
print(X_full.shape)
print(Y.shape)Sortie : (506, 13) (506,)
Notre dataset contient 506 lignes c’est-à-dire 506 logements. Chacun de ces logements contient 13 colonnes qui sont :
- CRIM – taux de criminalité par habitant par ville
- ZN – proportion de terrains résidentiels zonés pour des lots de plus de 25 000 pieds carrés.
- INDUS – proportion de terrains commerciaux non commerciaux par ville
- CHAS – variable muette Charles River (1 si la parcelle borde la rivière, 0 sinon).
- NOX – concentration d’oxydes nitriques (parties par 10 millions).
- RM – nombre moyen de pièces par logement
- AGE – proportion de logements occupés par leur propriétaire construits avant 1940
- DIS – distances pondérées à cinq centres d’emploi de Boston
- RAD – indice d’accessibilité aux autoroutes radiales
- TAX – taux de l’impôt foncier sur la pleine valeur par 10 000 $.
- PTRATIO – ratio élèves/professeurs par ville
- B – 1000(Bk – 0.63)^2 où Bk est la proportion de Noirs par ville
- LSTAT – % de la population de statut inférieur
Et la target qui est MEDV – Valeur médiane des maisons occupées par leur propriétaire, en milliers de $.
Maintenant qu’on a des informations sur notre dataset, on peut commencer concrètement l’analyse de nos données.
Analyser ses données – Projet Data Science
Le score de corrélation
Dans cette partie on va faire de la Data Analyse grâce à la librairie Scikit-learn.
Je rappelle que notre objectif est de prédire notre target Y à partir de nos features X.
On va donc tout d’abord déterminer pour quelle colonne X on peut le mieux prédire notre Y
On utilise pour ça la f_regression() qui calcule le score de correlation entre chacune de nos features et notre target.
Ensuite avec SelectKBest on choisit les K colonnes les plus corrélées. Dans notre cas k=1 donc on prend le feature le plus corrélé à notre target.
Dit simplement, cette opération nous permet d’extraire le feature qui permet le plus de prédire notre target.
Attention ici, le feature la plus corrélée du dataset n’implique pas qu’on peut prédire notre target avec. Cela indique seulement que c’est le meilleur feature à utiliser pour prédire notre target parmi les features du dataset.
from sklearn.feature_selection import SelectKBest, f_regression
selector = SelectKBest(f_regression, k=1)
selector.fit(X_full, Y)
X = X_full[:, selector.get_support()]
print(X.shape)Dans notre cas le feature avec le plus haut score de corrélation (aussi appelé k-highest score) est la dernière colonne de notre dataset. Cette info nous est donnée par la fonction selector.get_support().
Appelons-le feature-K.
Le feature-K
On extrait cette colonne pour faire une analyse plus détaillée de notre dataset.
Est-ce que la relation entre notre feature-K et notre target est linéaire ?
Si c’est le cas, la prédiction de notre target sera facile.
%matplotlib inline #uniquement sur notebook/colab
import matplotlib.pyplot as plt
plt.scatter(X, Y, color='#F4E29150')
plt.show()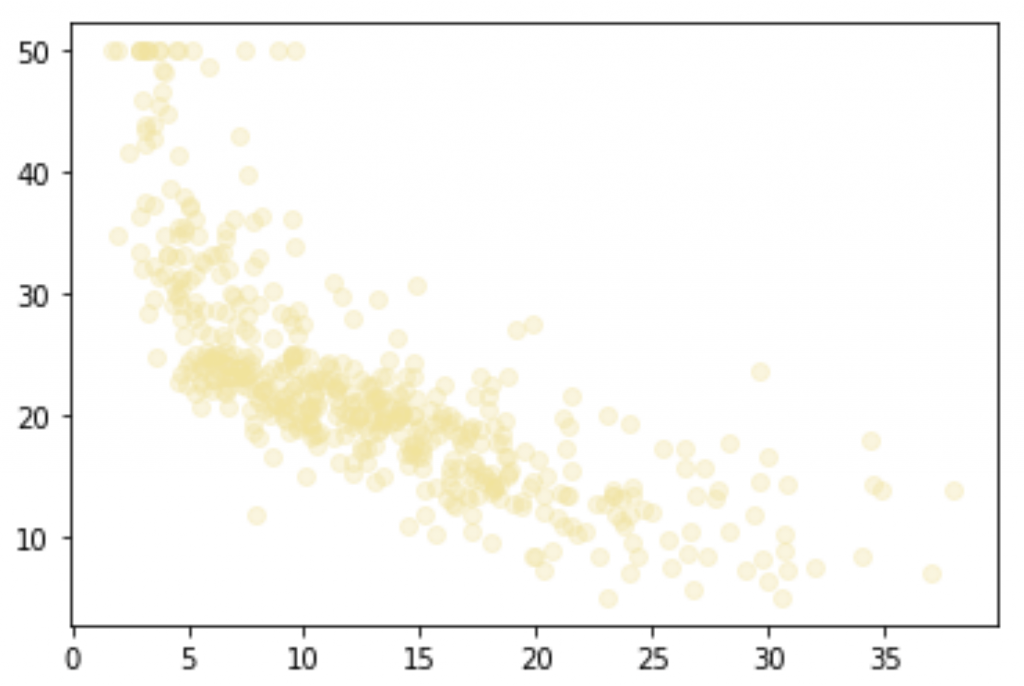
On voit qu’il y a une certaine corrélation. Effectivement quand X (feature-K) décroît, Y (target) décroît aussi. Mais la relation n’est pas évidente ni assez forte pour en conclure qu’il existe une relation linéaire entre notre feature-K et la target.
D’ailleurs comme tu le vois j’ai choisi comme couleur un jaune transparent #F4E29150. Le pourcentage d’opacité est déterminé par les 2 derniers chiffres. Ici on est à 50% d’opacité. Je n’ai pas fait ce choix au hasard. En fait en choisissant une couleur transparente, on peut repérer où s’entasse les données.
Effectivement quand une zone est composée de plusieurs points, elles devient de plus en plus opaque. Cela permet de repérer facilement où les données sont les plus présentes et inversement, de repérer où sont les données les plus disparates. Cela n’aurait pas été possible si l’opacité était de 100%.
Au fait, si ton objectif est d'apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :
À présent, on peut revenir à ce que je mentionnais précédemment.
En plus de l’axe X et Y, la couleur est un deuxième paramètre avec lequel jouer pour améliorer ton analyse.
Poursuivons notre analyse en utilisant les algorithmes de base de la Data Science. Cela nous permettra d’approfondir nos résultats.
Quelques algorithmes de Data Science pour bien débuter – Projet Data Science
Régression linéaire
Dans la partie précédente nous avons conclus qu’il y a une corrélation entre nos données feature-K et la target. Mais nous avons émis des doutes sur le fait que cette relation soit linéaire.
La relation linéaire est la première hypothèse à vérifier. Effectivement, c’est à la fois la plus simple à établir, mais aussi celle qui permet de résoudre le plus facilement un problème.
On va donc utiliser l’algorithme LinearRegression de la librairie Scikit-learn. Cet algorithme permet de tracer une droite qui minimise la distance entre elle et chacun des points.
Si chaque point de notre graphique est positionné sur la droite tracée, la relation entre X et Y est linéaire.
from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
regressor.fit(X, Y)
plt.scatter(X, Y, color='#F4E29150')
plt.plot(X, regressor.predict(X), color='#BDD5EA', linewidth=3)
plt.show()
Ici, on voit clairement que très peu de points sont positionnées sur la droite. On aurait pu être conciliant si la plupart des points étaient sur la droite et que seulement quelques-uns s’en éloignaient. Mais ici, c’est l’inverse. La plupart des points n’appartiennent pas à la droite tracée.
La relation entre nos feature-K et la target n’est donc pas linéaire.
Maintenant deux options s’offre à nous pour prédire notre target :
- Appliquer une transformation à nos feature-K pour créer une relation linéaire entre X et Y
- Utiliser d’autres algorithmes de la librairie scikit-learn
Je te propose de suivre la deuxième option ! 🔥
Le Support Vector Machine
On va commencer avec un algorithme de Support Vector Machine (SVM). Pour faire simple, cet algorithme fait la même que le LinearRegression, mais pour des relations non-linéaire.
Ici, au lieu d’avoir une droite, on aura une courbe.
Le SVM va donc tracer une courbe (en fait un ensemble de point) qui minimise la distance entre cette courbe et les autres points.
Si chaque point de notre graphique est positionné sur la courbe tracée, Y peut être prédit grâce au SVM.
Plusieurs types de SVM existent, dans notre cas on utilisera l’algorithme SVR (Epsilon-Support Vector Regression).
Je veux garder cette article le plus pratique possible donc je ne rentrerai pas dans les détails de l’algorithme. Néanmoins si vous voulez en savoir plus, n’hésitez pas à aller sur la page Wikipédia du SVM ou directement sur la documentation de scikit-learn.
from sklearn.svm import SVR
regressor = SVR()
regressor.fit(X, Y)
plt.scatter(X, Y, color='#F4E29150')
plt.scatter(X, regressor.predict(X), color='#BDD5EA50', linewidth=3)
plt.show()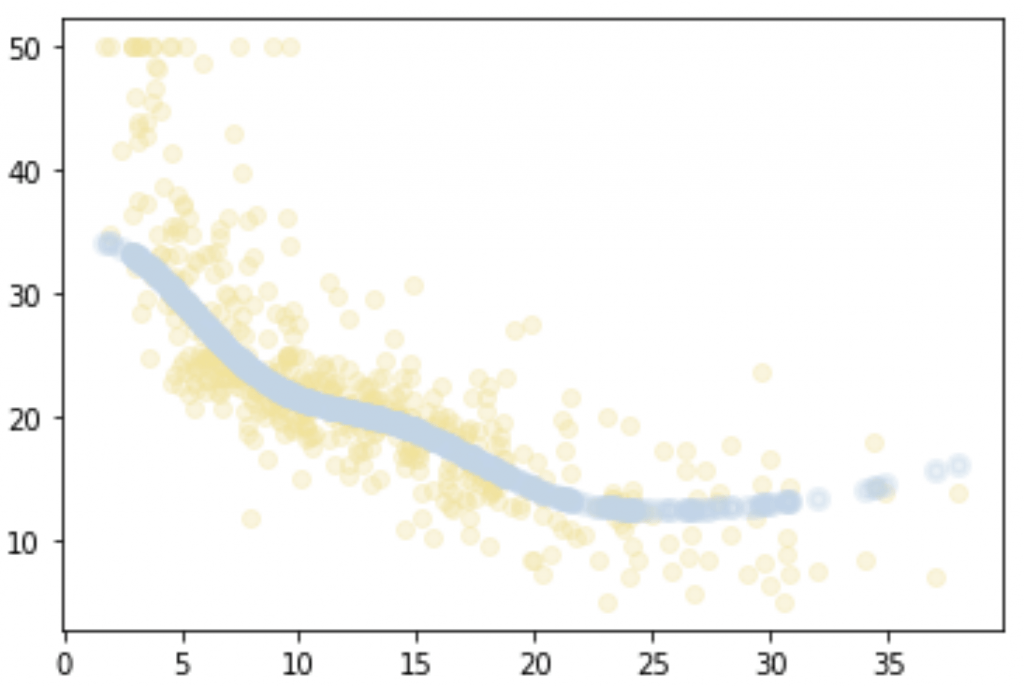
La courbe s’adapte beaucoup plus à nos données que la droite de régression linéaire !
Effectivement on voit que nos points semblent passer en plein milieu de notre amas de données (en bas à gauche).
On est sur la bonne voie !
Voyons tout de même si l’on peut faire mieux avec un autre algorithme : le Random Forest, ou Forêt Aléatoire.
Random Forest
Un des algorithmes que tu rencontreras le plus souvent.
Plusieurs mots techniques à retenir vont suivre…
En fait, le Random Forest rassemble en lui-même plusieurs algorithmes. C’est ce qu’on appelle de l’Ensemble Learning (ou Apprentissage ensembliste).
L’Ensemble Learning, c’est le fait d’utiliser plusieurs algorithmes à la fois pour obtenir une meilleur performance.
Le Random Forest utilise un ensemble d’algorithme Decision Tree (ou Arbre de Décision).
Un Decision Tree est un algorithme qui permet de faire une prédiction ou une classification. Il crée un schéma en forme d’arbre qui présente les possibilités selon les informations que l’on possède.
Voici un exemple de Decision Tree :
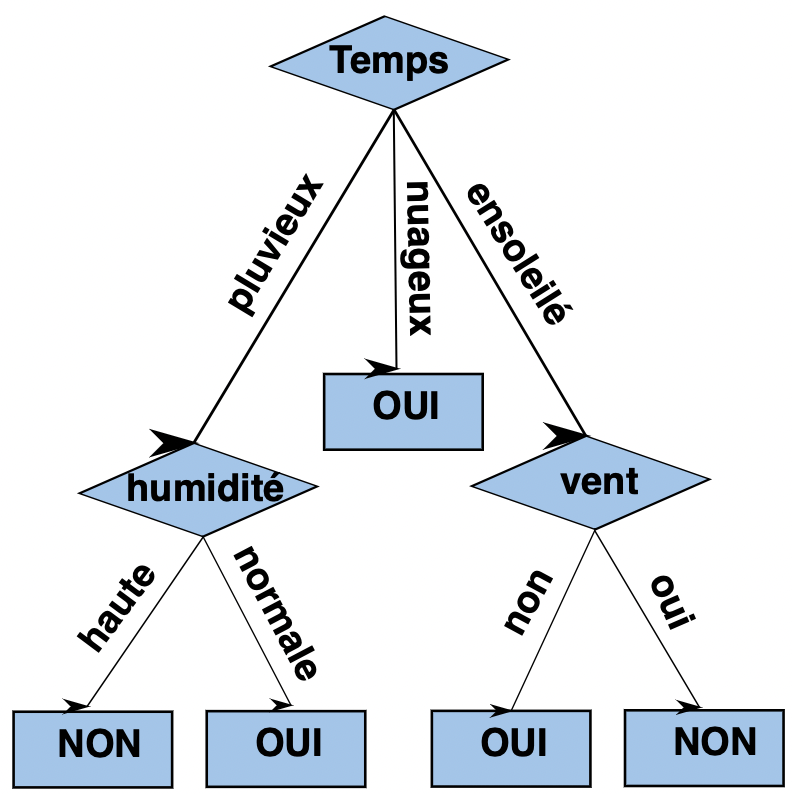
Dans un Random Forest on va ainsi utiliser plusieurs Decision Tree pour optimiser nos résultats. Pour cela on utilise l’algorithme RandomForestRegressor de Scikit-learn.
from sklearn.ensemble import RandomForestRegressor
regressor = RandomForestRegressor()
regressor.fit(X, Y)
plt.scatter(X, Y, color='#F4E291');
plt.scatter(X, regressor.predict(X), color='#BDD5EA50', linewidth=3)
plt.show()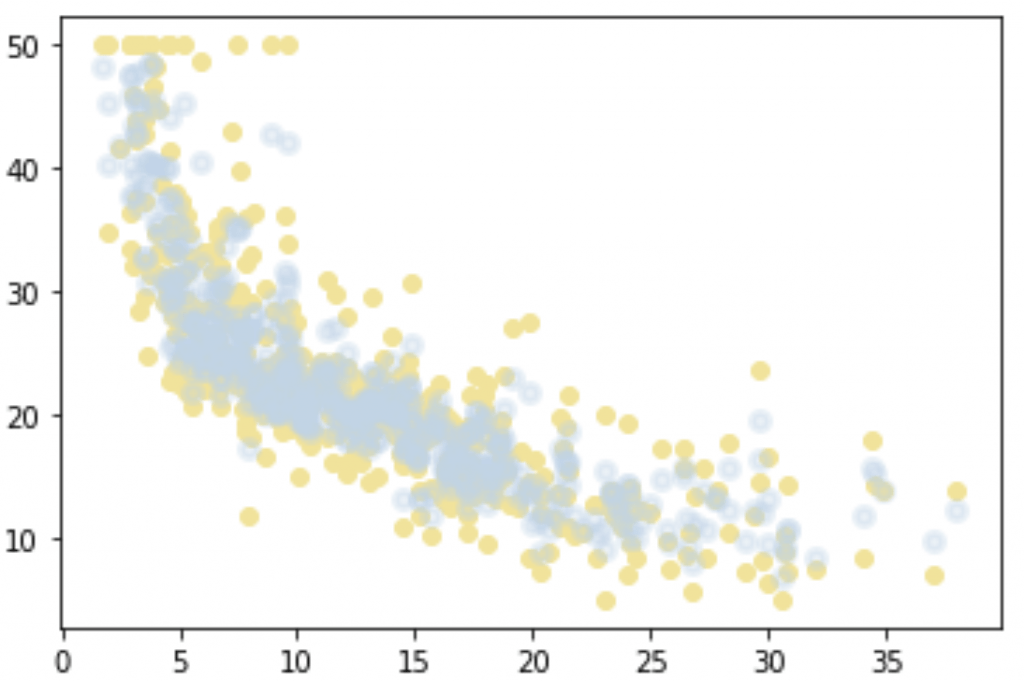
Le résultat est parfait ! Les points créés par le Random Forest sont très bien adaptés à notre problème.
C’est la fin de ton premier projet de Machine Learning !
Tu as pu voir les techniques fondamentale de l’analyse de données et utiliser les algorithmes de bases du Machine Learning grâce à Scikit-learn.
La Data Science est une base essentielle pour créer des algorithmes de Machine Learning.
Mais aujourd’hui, c’est grâce au Deep Learning que les leaders de la tech peuvent créer les Intelligences Artificielles les plus puissantes.
Si tu veux approfondir tes connaissances dans le domaine, tu peux accéder à mon Plan d’action pour Maîtriser les Réseaux de neurones.
Un programme de 7 cours gratuits que j’ai préparé pour te guider dans ton parcours pour apprendre le Deep Learning.
Si ça t’intéresse, clique ici :
sources :
- Alberto Boschetti – Python Data Science Essentials
- Decision Tree – Github
Un dernier mot, si tu veux aller plus loin et apprendre le Deep Learning - j’ai préparé pour toi le Plan d’action pour Maîtriser les Réseaux de neurones.
7 jours de conseils gratuits d’un ingénieur spécialisé en Intelligence Artificielle pour apprendre à maîtriser les réseaux de neurones à partir de zéro :
- Planifie ton apprentissage
- Structure tes projets
- Développe tes algorithmes d’Intelligence Artificielle
J’ai basé ce programme sur des faits scientifiques, des approches éprouvées par des chercheurs mais également mes propres techniques que j'ai conçues au fil de mes expériences dans le domaine du Deep Learning.
Pour y accéder, clique ici :



Merci